

Data is everywhere—but not all of it is useful. Just because you have data doesn’t mean you can trust it. Wrong addresses, duplicate records, outdated entries—these small issues can cause big problems in decision-making, reporting, and customer service.
That’s where data quality comes in. It’s the difference between clear insight and costly mistakes. If your data is accurate, complete, and consistent, everything runs smoother—analytics are sharper, operations move faster, and teams make better calls.
This guide breaks down how to measure data quality clearly and practically. Whether you’re managing systems, building reports, or leading a data team, this will help you understand what to track, how to check for errors, and what tools to use. Let’s get into it.
What Is Data Quality?
Data quality means how reliable and useful your data is for making decisions. In business, it’s not enough to just have data—you need data that’s correct, complete, consistent, and ready to use. Good data quality helps teams act fast, reduce mistakes, and trust what they see in reports or dashboards.
It’s easy to confuse data quality with terms like accuracy or integrity, but they’re not the same. Accuracy is one part of data quality—it checks if the data matches the real world. Data integrity focuses on whether the data stays correct as it moves across systems or gets updated. Data quality is the bigger picture—it covers all the parts that make data useful in real life.
Measuring data quality becomes essential as your business grows. More systems, more automation, and more analytics mean more room for bad data to spread. Without clear checks, you’ll waste time cleaning up errors, miss insights, or make wrong calls. That’s why putting a system in place to measure and track quality early on saves time, money, and trust in the long run.
The 6 Core Dimensions of Data Quality
Data quality isn’t one thing—it’s a combination of key traits that work together. These six dimensions give you a clear way to check if your data is actually useful. Here’s what each one means, why it matters, and how to measure it.
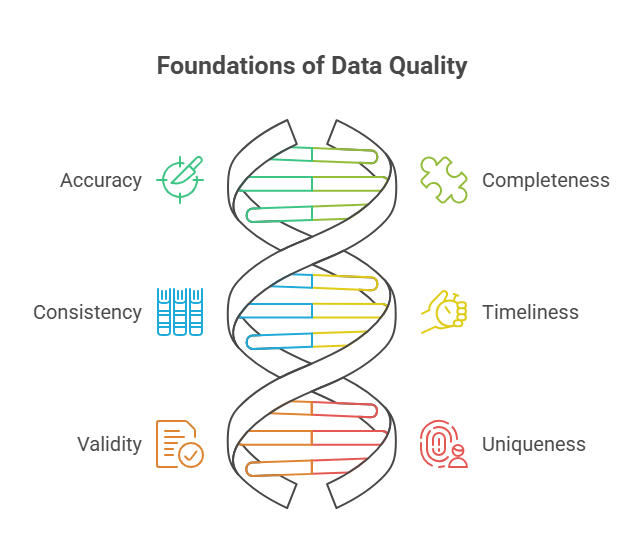
Accuracy
What it means:
Accuracy checks whether your data reflects the real world. If a customer’s name, address, or purchase history is wrong, any decision based on that data will likely be wrong too.
Why it matters:
Inaccurate data leads to poor customer experiences, wrong reporting, and wasted time. Even small mistakes can snowball—especially in marketing, billing, or analytics.
How to measure it:
- Compare records against verified sources (e.g., government databases, customer confirmations).
- Run validation rules that flag known errors (like typos or wrong formats).
- Audit a random sample manually to see if the data holds up.
Completeness
What it means:
Completeness means no required information is missing. It’s not just about having data—but having all the data you need.
Why it matters:
Incomplete records block automation and slow down teams. For example, a missing phone number can stall a sales call or delay support.
How to measure it:
- Check for empty fields in key data (like emails, IDs, product SKUs).
- Define what “complete” looks like for each record type.
- Track how often required fields are filled out across your dataset.
Consistency
What it means:
Consistency ensures data doesn’t contradict itself across different systems or formats. One version of the truth—no matter where you look.
Why it matters:
Inconsistent data causes confusion. It hurts trust, misguides reporting, and breaks workflows. A product listed at two prices across systems can easily cause a billing mess.
How to measure it:
- Compare records across databases or platforms for mismatched values.
- Use golden records or master data to act as your single source of truth.
- Write scripts to catch conflicts or duplicates in logic.
Timeliness
What it means:
Timeliness looks at how current the data is. If the data is too old, it’s often as useless as having no data at all.
Why it matters:
Outdated data leads to missed opportunities and poor decisions. In fast-moving areas like logistics or marketing, timing is everything.
How to measure it:
- Measure the delay between when something happens and when it’s recorded.
- Set limits for how “fresh” different data types should be.
- Analyze how old your data is across key fields.
Validity
What it means:
Validity checks if data fits expected formats and rules. Think of it as “does this even make sense?”
Why it matters:
Invalid data can break systems and throw off logic. An email with no “@” or a date in the wrong format can block forms or ruin exports.
How to measure it:
- Run schema validation checks (e.g., for emails, dates, currency).
- Use logic rules to catch outliers or impossible values.
- Validate entries against known lists (like country codes or product categories).
Uniqueness
What it means:
Uniqueness means there are no accidental duplicates. Each record should stand on its own, without repeating another.
Why it matters:
Duplicate data causes double charges, repeated emails, or inflated reporting. It wastes storage and damages user trust.
How to measure it:
- Use scripts or tools that find near-duplicates through fuzzy matching.
- Run checks using primary or composite keys to find duplicates.
- Monitor the frequency of duplicates over time.
How to Set Up a Data Quality Assessment Framework
Measuring data quality once isn’t enough. You need a clear system that runs regularly, stays aligned with your business goals, and assigns responsibility for fixing problems. Here’s how to build a practical, repeatable framework that actually works.
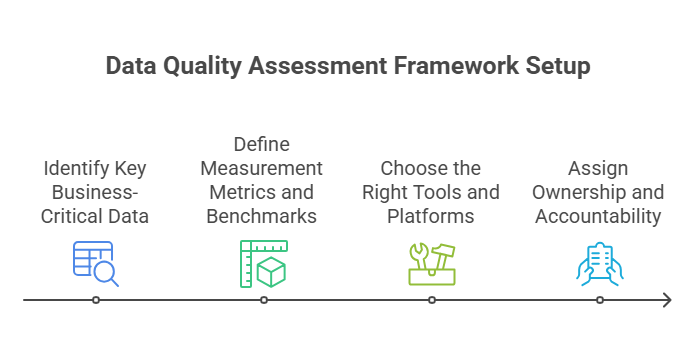
Identify Key Business-Critical Data
Start by figuring out which data matters most to your business. This usually includes:
- Customer data (names, contact info, preferences)
- Product data (SKUs, descriptions, prices)
- Financial data (transactions, billing details)
- Operational data (inventory, scheduling, delivery records)
Focus on the data that supports daily operations, reporting, compliance, or customer experience. If it drives decisions or affects customers, it’s critical.
Next, tie this data to business outcomes. What’s the cost of errors? What processes rely on it? This will help you prioritize what to measure and where to invest time.
Define Measurement Metrics and Benchmarks
Once you’ve picked the data to assess, define how you’ll measure its quality.
- Set error thresholds: Decide what’s acceptable. For example, you might allow 1% missing fields in contact records but zero duplicates in invoices.
- Create SLAs for each dimension: For example, “Customer data must be 98% accurate and 95% complete every month.”
- Decide how often to check: Weekly, monthly, or in real-time—this depends on how fast your data changes.
Use these benchmarks to track trends, spot issues early, and hold teams accountable.
Choose the Right Tools and Platforms
You don’t have to measure everything manually. Use tools that help automate profiling, cleansing, and reporting.
Popular options include:
- Talend – Open-source and enterprise versions with strong data integration features.
- Informatica – Good for large enterprises with complex pipelines.
- Microsoft Purview – Built for Azure users with governance and catalog features.
- OpenRefine – Lightweight and free, ideal for smaller cleanup jobs.
Compare tools based on:
- Ease of use
- Integration with your existing tech stack
- Real-time vs. batch processing
- Support for profiling, validation, and reporting
Assign Ownership and Accountability
Data quality isn’t just an IT issue. You need clear roles for monitoring and fixing problems.
- Data stewards usually own the accuracy and upkeep of specific data sets.
- Data governance teams define the rules, build policies, and make sure standards are followed.
Spell out who reviews quality metrics, who fixes what, and who’s responsible for prevention. Without ownership, even the best framework falls apart.
Common Challenges in Measuring Data Quality
Even with the right tools and goals in place, measuring data quality can hit roadblocks. Here are five of the most common issues teams face—and why they matter.
1. Data Spread Across Too Many Systems
When data is scattered across CRMs, spreadsheets, internal tools, and third-party platforms, it’s hard to get a full view. You may find customer details stored in five places, all slightly different. Without central access, measuring consistency, accuracy, or completeness becomes guesswork.
2. No Standard Definitions for “Good” Data
Different teams often have different rules. One department might allow blank fields, while another flags them as errors. Without agreed-upon standards, you can’t measure or improve quality in a meaningful way.
3. Limited Tools or Manual Work
Some businesses rely too much on manual checks or outdated tools. That slows everything down and increases the chance of human error. It also makes it hard to run regular assessments or scale up as your data grows.
4. Lack of Clear Ownership
If no one owns the data, no one fixes it. Data issues often fall between departments, with each team assuming someone else will handle it. Without assigned roles, even simple errors stay unresolved for months.
5. Low Buy-In from Teams
If employees don’t see why data quality matters, they won’t prioritize it. Teams may skip validation steps or enter sloppy data just to save time. Without clear value or feedback loops, it’s hard to build a culture of accountability.
Best Practices to Continuously Improve Data Quality
Improving data quality isn’t a one-time fix. It’s a habit that needs the right systems, people, and mindset. Below are practical steps that help keep your data clean, reliable, and ready for use.
- Automate Data Quality Monitoring
Manual checks don’t scale. Automate routine tasks like flagging missing fields, catching duplicates, or checking formats. Set up validation rules inside forms, CRMs, and ETL pipelines so bad data doesn’t get in at all.
Use automated reports or dashboards to track quality metrics over time. This makes it easy to spot trends, fix recurring problems, and hold teams accountable without slowing them down.
- Build Data Quality into Daily Workflows
Quality shouldn’t feel like extra work. Make it part of how your team already operates. Add simple checks at data entry points, and build alerts that notify users when they input something wrong or incomplete.
The goal is to fix issues at the source, not weeks later. The cleaner your input, the fewer fixes you’ll need down the line.
- Embed Quality Standards in Policies
Set clear rules for each type of data—what’s required, what formats are allowed, and who’s responsible for what. Make sure everyone uses the same definitions and follows the same process.
Document these standards and share them across teams. Consistency starts with clarity.
- Train Teams and Build Data Awareness
If people don’t understand why data quality matters, they won’t protect it. Give short, focused training on how bad data affects their work and how to avoid common mistakes.
You don’t need long seminars. Even a 15-minute session on avoiding duplicate entries or checking for missing fields can improve habits fast.
- Track and Report Data Quality KPIs
What gets measured gets managed. Set a few key metrics for each core dimension (accuracy, completeness, timeliness, etc.), and review them regularly.
Use simple dashboards that everyone can understand. Share progress, wins, and areas that need attention. This keeps quality visible and makes it easier to get buy-in for improvements.
Conclusion
You don’t need perfect data—you need dependable data. The goal isn’t to fix everything at once, but to build habits, tools, and checks that make high-quality data the default over time.
Start small. Pick one key dataset, define what “good” looks like, and measure it regularly. Then expand from there. Don’t wait for a major cleanup project or system overhaul—build quality into what your team already does.
Data quality isn’t just about clean records. It’s about better decisions, faster work, and fewer headaches later. When your team trusts the data, they move with more speed and confidence. That’s how you scale smart, not just fast.


