

Data is everywhere—and businesses depend on it to make decisions, track performance, and build products. But raw data isn’t useful on its own. It needs structure, movement, and reliability. That’s where data engineers come in.
They build the pipelines, tools, and systems that move data from one place to another—cleanly and consistently—so it’s ready for analysis.
As more companies go data-first, the demand for skilled data engineers is growing fast. If you’re wondering how to break into this field, this guide is for you. We’ll walk through the exact skills to learn, tools to master, ways to build real-world experience, and how to land your first job—step by step.
Let’s get started.
Step One: What Does a Data Engineer Do?
A data engineer builds the systems that collect, process, and deliver data so others—like analysts and data scientists—can use it to make decisions.
Their main job is to create and manage data pipelines—automated workflows that pull raw data from different sources (like apps, websites, or databases), clean it, and send it to storage systems like data warehouses or data lakes.
They don’t focus on analyzing data themselves. Instead, they make sure it’s:
- Accurate (not full of errors)
- Available (stored in the right place)
- Fast-moving (delivered on time)
To do this, they build ETL processes (Extract, Transform, Load), write code (usually in Python and SQL), and work with tools like Apache Spark, Airflow, and cloud services (AWS, GCP, or Azure).
In short, data engineers are the ones who make sure data flows smoothly behind the scenes—so others can use it to build models, dashboards, and reports that guide real business decisions.
Step Two: Five Core Skills Required to Become a Data Engineer
If you’re serious about starting a career in data engineering, these skills aren’t just helpful—they’re required. This isn’t a job you can “figure out later.” You need a strong foundation in the right tools, languages, and thinking patterns from day one. Here’s exactly what you need to learn:
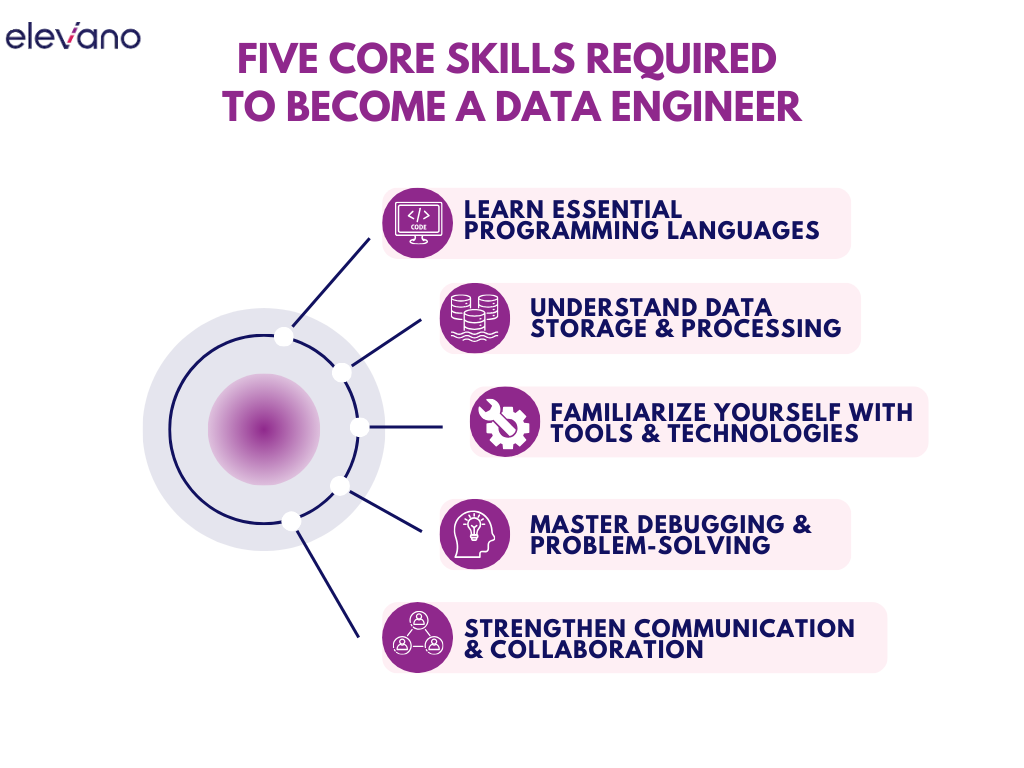
1. Programming Languages You Must Learn
There’s no way around it—if you want to work with data, you have to code.
- Python is the top language used in data teams. You’ll use it for automation, data processing, and building pipelines. Learn it well.
- SQL is a must. You’ll write queries constantly. It’s the language of data.
- Scala or Java may not be required at first, but if you plan to work on big data platforms, at least one of these will give you an edge.
Bottom line: If you can’t write code, you can’t do the job.
2. Data Storage and Processing
You need to understand where data lives, how it moves, and how to shape it.
- Master both relational (SQL) and non-relational (NoSQL) databases. You’ll work with both.
- Learn data modeling—it’s how you make systems fast, scalable, and reliable.
- Study ETL pipelines—this is the core of what you’ll build as a data engineer.
You’re not just moving data—you’re shaping how a business runs on it.
3. Tools and Technologies You’ll Work With
These are the tools that run real-world data systems. Employers expect you to know them—or be ready to learn fast.
- Apache Spark and Hadoop for big data processing
- Airflow to schedule and manage workflows
- Redshift, BigQuery, Snowflake for modern data warehousing
- AWS, GCP, Azure for cloud infrastructure
Knowing the theory isn’t enough—learn the tools that power real data teams.
4. Debugging and Problem-Solving
Things will break. It’s your job to find out why and fix it fast.
- Learn how to read logs, test components, and isolate problems.
- Break down issues into steps and stay calm under pressure.
- Always be thinking: How can I make this more reliable next time?
If you can’t solve problems under pressure, this job will be tough.
5. Communication and Collaboration
Data engineers don’t work in isolation. You’ll constantly work with teams across the company.
- Learn to explain complex systems in simple terms.
- Ask the right questions to understand data needs clearly.
- Be ready to work in Agile teams and contribute to shared goals.
Your code won’t matter if no one understands what it does or why it’s needed.
Step Three: Where and How to Learn Data Engineering Skills
You don’t need a degree to get started, but you do need solid skills. Whether you’re self-taught or college-trained, what matters is what you can build.
Do You Need a Degree?
A degree in computer science or data-related fields helps, but it’s not required. Many data engineers break in through self-study, projects, or bootcamps. If you can prove your skills, the degree won’t matter.
Learn Faster with Online Courses or Bootcamps
Online platforms are a great way to learn what the job really needs:
- Coursera – Google’s data engineering course
- Udacity – Hands-on Nanodegree
- DataCamp – Great for Python, SQL, ETL
Bootcamps are faster, more intense, and often job-focused.
Pick one path and stick with it—depth matters more than jumping around
Certifications That Matter
Certs aren’t required, but they help if you’re new and want to stand out:
- Google Cloud: Professional Data Engineer
- AWS Certified Data Analytics – Specialty
- Databricks Data Engineer Associate
Don’t collect them all. Pick one, learn it well, and back it up with a real project.
Step Four: How to Gain Practical Experience
Learning the theory is good, but employers want proof you can apply it. Practical experience is what turns skills into a career. Here’s how to get it—without needing a job first.
Build Real Projects That Show What You Can Do
Start with projects that solve real problems using real tools. A few solid examples:
- Build a data pipeline that pulls public data and stores it in a warehouse
- Create an ETL process that cleans and transforms messy data
- Stream stock price updates or tweets using Kafka or Spark Streaming
Put your code on GitHub with clear README files, comments, and screenshots. This becomes your portfolio—and it’s often more valuable than a resume alone.
No one hires based on what you know. They hire based on what you’ve done.
Try Internships or Freelance Gigs
Internships, even unpaid ones, can give you hands-on experience and credibility. Look on LinkedIn, Handshake (for students), or AngelList (for startups).
If you already know the basics, reach out to small businesses or local startups. Offer to build simple data systems—like dashboards or reports—in exchange for experience or testimonials.
You don’t need a big name on your resume. You need real work to talk about.
Contribute to Open Source Projects
Open source lets you learn from others and build things that matter. It also shows employers you can work on a team and write clean, useful code.
Search GitHub for data engineering projects tagged with “good first issue” or check sites like Up For Grabs and First Timers Only.
Even small contributions—like fixing bugs or writing docs—count.
Open source is one of the best ways to get real experience without asking for permission.
Step Five: How to Land Your First Job as a Data Engineer
Once you’ve built your skills and portfolio, the next step is turning that into a job. Here’s how to present yourself, prep for interviews, and find the right opportunities.
Make Your Resume and LinkedIn Work for You
Focus on what matters to hiring managers: tools you’ve used, projects you’ve built, and certifications you’ve earned. Lead with outcomes—show what you built and why it mattered.
Tailor your resume for each job. Use the same keywords from the job post and highlight relevant tools or experience near the top.
Your LinkedIn should match your resume and include a short summary, links to projects, and a clean work history. Recruiters check it—even if you apply elsewhere.
You don’t need a long resume. You need a clear one.
Prepare for Interviews Like a Real Project
Expect questions on SQL, Python, ETL design, cloud platforms, and debugging. You may also be asked to build or explain a pipeline.
Use platforms like Interviewing.io, Pramp, or Exercism to practice mock interviews and technical challenges. Review your own past projects so you can walk through how you built them.
If you can explain it clearly, you understand it well enough to get hired.
Know Where to Find Entry-Level Jobs
Start with big platforms:
- LinkedIn (use filters for “entry-level” and “remote”)
- Indeed
- Hired.com
Go beyond job boards. Join Slack or Discord groups focused on data engineering. Many job leads are shared there before they go public. Also follow hiring managers and tech leads on LinkedIn.
The more visible you are in the community, the more chances come your way.
How To Grow your Career with Specialization Options
Getting your first job is a win—but it’s just the beginning. Data engineering has plenty of room to grow, both in skills and salary. Here’s where your path can lead as you level up.
Mid to Senior-Level Career Paths
Once you’ve got a few years of experience, you can move into higher-impact roles:
- Senior Data Engineer – Leads complex projects, mentors junior engineers, and designs large-scale systems. You’ll be trusted to solve harder problems with less supervision.
- Data Architect – Focuses on the big picture. Architects plan how all data systems fit together and scale across the company. This role mixes technical depth with long-term planning.
- Engineering Manager – If you enjoy working with people and driving team goals, this role blends leadership and project delivery. Less coding, more team building.
As you grow, your impact shifts from writing code to shaping how data is used across the business.
Specialization Options to Deepen Your Expertise
Instead of going broad, you can also go deep. These are fast-growing areas where companies need specialized skills:
- Streaming Data Pipelines – Focuses on real-time data flow using tools like Kafka, Flink, or Spark Streaming. Great for apps that need instant updates—like stock prices or live metrics.
- Cloud-Native Data Infrastructure – Specialize in building on cloud services like AWS, GCP, or Azure. You’ll design systems that scale fast and stay reliable with minimal hands-on maintenance.
- Machine Learning Infrastructure – Helps data scientists deploy models into production. You’ll build pipelines that move data into and out of training workflows, often using ML tools and APIs.
These niches pay well and open doors to more advanced roles—and they start with the same foundation you’re building now.
Conclusion
Starting a career in data engineering isn’t about memorizing every tool or chasing endless certifications—it’s about building a strong foundation, proving you can apply it, and showing employers you can deliver real results.
If you follow the steps in this guide—learn the core skills, build projects, share your work, and get involved in the data community—you’ll already be ahead of most beginners. From there, it’s about staying consistent and growing your expertise in areas that interest you, whether it’s cloud infrastructure, real-time streaming, or machine learning pipelines.
The companies hiring data engineers today aren’t just looking for people who “know” data—they’re looking for people who can make it flow, keep it clean, and make it usable. If you can do that, you’ll always be in demand.
So start now. Pick one skill, one project, and one platform to learn on. Build, share, improve, and repeat. Your first role in data engineering could be closer than you think.


