

Landing a data engineer job in 2025 takes more than knowing a few buzzwords—it’s about proving you can build and manage systems that keep data flowing smoothly. Picture this: companies generate mountains of data daily, but without skilled engineers, it’s like having a library with no shelves. Interviews are where you show you can organize that chaos.
This guide brings you real questions and practical tips so you can step into the interview ready to talk about pipelines, databases, and problem-solving—not just theory. We’ll move from technical challenges to real-life scenarios and end with smart preparation strategies, making sure you know what matters most to employers today.
Understanding the Role of a Data Engineer
A data engineer builds the systems that collect, store, and deliver data for analysis. Think of them as the people who create the highways for data to travel on so analysts, scientists, and business teams can use it to make decisions.
Their main responsibilities include:
- Designing and managing data pipelines so that information flows quickly and accurately.
- Building and maintaining databases that can handle large amounts of data without slowing down.
- Cleaning and organizing data to make sure it’s correct and ready to use.
- Working with tools and platforms like SQL, Python, Spark, and cloud services such as AWS or Google Cloud.
Unlike data scientists who focus on analyzing and interpreting data, data engineers focus on the infrastructure that makes analysis possible. Both roles are important, but without engineers, there’s no reliable data for anyone to analyze.
Types of Data Engineer Interview Questions
Data engineer interviews test three main things: your technical skills, how you handle real-world problems, and whether you can work well with others. Let’s break this down so you know exactly what to expect.
1. Technical Questions
These check your knowledge of the tools and skills needed for the job. You can expect questions about:
- SQL and databases: Writing queries, designing tables, and improving performance.
- Data pipelines and ETL tools: Moving and transforming data efficiently.
- Big Data frameworks: Working with tools like Spark or Hadoop.
- Cloud platforms: Using AWS, Google Cloud, or Azure for data storage and processing.
- Programming skills: Writing clean, efficient code—often in Python or Java.
2. Scenario-Based Questions
Here, you get real-world problems to solve. Examples include:
- How you’d fix a slow pipeline.
- What steps would you take if data were missing or corrupted?
- Designing a system for both real-time and batch data processing.
These show your problem-solving approach and whether you can think on your feet.
3. Behavioral and HR Questions
Employers also want to see if you fit well with the team. They might ask about:
- Times you solved a problem under pressure.
- How you explained technical concepts to non-technical coworkers.
- Ways you’ve handled conflicts or tight deadlines.
Top Data Engineer Interview Technical Questions and Answers
Data engineer interviews often go deep into technical areas to see if you can build reliable, scalable systems. Below is a breakdown by topic with sample questions, quick answer tips, and common mistakes to avoid.
1. SQL and Database Questions
Sample Questions
- “Write a query to find the second-highest salary from the employees table.”
- “How would you optimize a slow-running query?”
- “Explain the difference between clustered and non-clustered indexes.”
Quick Answer Tips
- Use ROW_NUMBER() or LIMIT/OFFSET for ranking queries.
- For optimization, suggest indexes, query refactoring, and analyzing execution plans.
- Explain concepts simply—e.g., “A clustered index defines the table’s physical order; non-clustered is like a separate lookup.”
Common Mistakes
- Writing complex queries without testing edge cases.
- Forgetting performance implications on large datasets.
- Ignoring normalization and data integrity rules.
2. Data Modeling and Architecture
Sample Questions
- “What’s the difference between a star schema and a snowflake schema?”
- “How would you design a data warehouse for a retail company tracking sales and inventory?”
Quick Answer Tips
- Star schema: Fewer joins, better for performance; ideal for simpler analytics.
- Snowflake schema: More normalized, less redundancy; better for storage efficiency.
- When designing warehouses, focus on fact and dimension tables, granularity, and query speed.
Common Mistakes
- Over-normalizing schemas causes performance bottlenecks.
- Ignoring the business reporting needs when modeling data.
3. ETL and Data Pipelines
Sample Questions
- “How would you automate a daily ETL process?”
- “What tools do you use for workflow scheduling?”
Quick Answer Tips
- Mention tools like Apache Airflow or Luigi for scheduling and orchestration.
- For incremental loads, highlight strategies like change data capture (CDC) or timestamp-based loading.
Common Mistakes
- Not handling error logging or retry mechanisms in pipelines.
- Loading entire datasets every time instead of using incremental loads.
4. Big Data and Cloud Platforms
Sample Questions
- “How would you optimize a Spark job that’s running too slowly?”
- “What’s the difference between AWS Redshift and Google BigQuery?”
Quick Answer Tips
- For Spark, suggest partitioning, caching, and tuning the number of executors.
- For cloud platforms, discuss serverless options, scalability, and cost considerations.
Common Mistakes
- Ignoring data partitioning and shuffle costs in Spark jobs.
- Using on-premises designs in cloud-native environments without taking advantage of auto-scaling or pay-as-you-go models.
5. Programming and Scripting
Sample Questions
- “Write a Python script to read a large CSV file and load it into a database efficiently.”
- “How would you remove duplicate records in a dataset using Python or SQL?”
Quick Answer Tips
- For large files, suggest chunked processing or tools like Dask.
- For deduplication, use window functions in SQL or Pandas drop_duplicates() in Python.
Common Mistakes
- Writing single-threaded code for tasks that could be parallelized.
- Not handling exceptions or data validation properly.
6. Additional High-Value Topics to Expect
Data Security and Governance
- “How would you handle personally identifiable information (PII) in your pipelines?”
- Focus on encryption, masking, and access controls.
Real-Time Data Processing
- “When would you use Apache Kafka instead of batch processing?”
- Explain streaming use cases like fraud detection or live analytics dashboards.
Performance Monitoring
- “How do you track the health of your data pipelines?”
- Mention monitoring tools, alerts, and metrics like latency and throughput.
Scenario-Based Interview Questions
Scenario questions test how you handle real-world challenges, not just theory. Employers want to see your problem-solving skills, structured thinking, and practical approach when things go wrong or requirements change suddenly.
1. Handling Pipeline Failures
Sample Question
- “Your data pipeline failed overnight. How would you handle it?”
What Interviewers Expect
- Immediate steps: Checking logs, error messages, and alert systems.
- Root cause analysis: Finding why it failed (e.g., missing data, network issue).
- Communication: Informing stakeholders about delays and expected resolution time.
- Prevention: Proposing fixes like alerts, retries, or better monitoring.
Common Mistakes
- Focusing only on fixing the problem without explaining preventive measures.
- Ignoring how downtime affects the business.
2. Managing Real-Time vs. Batch Data Requirements
Sample Question
- “We have both real-time and nightly batch data needs. How would you design the system?”
Quick Answer Framework
- Segmentation: Real-time for streaming tools (e.g., Kafka, Spark Streaming). Batch for daily aggregations.
- Storage: Use separate storage layers if needed (e.g., streaming DB + warehouse).
- Cost-performance balance: Real-time, where speed matters, batch, where cost matters.
Common Mistakes
- Suggesting real-time for everything, leading to unnecessary costs and complexity.
3. Handling Corrupted or Missing Data
Sample Question
- “What steps would you take if reports show incorrect or missing data?”
Quick Answer Framework
- Verify source data first.
- Check ETL transformations for errors.
- Implement validation checks and alerts to catch issues early.
Common Mistakes
- Jumping to code fixes before verifying the problem source.
- Not mentioning automated checks for the future.
4. Scaling Data Systems for Growth
Sample Question
- “Our data volume will double in the next six months. How would you prepare our systems?”
Quick Answer Framework
- Suggest partitioning, distributed storage, and scalable cloud solutions.
- Automate pipeline scaling with load balancers and auto-scaling groups.
Common Mistakes
- Ignoring cost optimization while proposing bigger infrastructure.
5. Working Under Tight Deadlines
Sample Question
- “What would you do if the CEO needs a critical report in two hours, but the data pipeline is running slowly?”
Quick Answer Framework
- Prioritize the quickest temporary fix (manual extraction or partial data).
- Explain the trade-offs clearly.
- Plan a long-term pipeline improvement afterward.
Common Mistakes
- Only focusing on technical fixes, ignoring the business urgency.
Behavioral and Soft Skill Questions
Technical skills get you in the door, but employers also want to know if you can work well with people, handle pressure, and communicate clearly. These questions help them see how you think, lead, and collaborate beyond just writing code.
1. Teamwork and Collaboration
Sample Question
- “Tell us about a time you worked with analysts or scientists to solve a data problem.”
What Interviewers Expect
- Clear story using the STAR method (Situation, Task, Action, Result).
- Examples where you explained technical ideas to non-technical people.
- Evidence of teamwork: meetings, brainstorming, joint debugging sessions.
Common Mistakes
- Talking only about your contribution without acknowledging the team’s effort.
- Giving vague answers without measurable outcomes.
2. Communication Skills
Sample Question
- “How do you explain technical data concepts to business stakeholders?”
Quick Answer Tips
- Use simple language and analogies instead of jargon.
- Share visuals like dashboards or diagrams to make complex points clearer.
- End with insights that connect to business value rather than just technical details.
Common Mistakes
- Overloading stakeholders with unnecessary technical depth.
- Forgetting to tie data insights to real decisions or outcomes.
3. Problem-Solving Under Pressure
Sample Question
- “Describe a time when a major data issue came up right before a big launch. What did you do?”
Quick Answer Framework
- State the problem briefly → Explain your action steps → Show results and lessons learned.
- Highlight calm decision-making and clear communication.
Common Mistakes
- Focusing too much on the technical fix without showing leadership or ownership.
4. Conflict Resolution
Sample Question
- “Tell us about a disagreement with a coworker and how you handled it.”
Quick Answer Tips
- Keep it professional; don’t badmouth coworkers.
- Show you listened, understood their view, and found a solution that worked for both sides.
Common Mistakes
- Making the story about who was right instead of how the conflict was resolved.
5. Time Management and Prioritization
Sample Question
- “How do you handle multiple data requests with tight deadlines?”
Quick Answer Tips
- Mention task prioritization, communicating realistic timelines, and automating repetitive work.
- Show that you balance speed with accuracy instead of rushing.
Common Mistakes
- Saying you “just work harder” without a real system for managing tasks.
Tips to Prepare for a Data Engineer Interview
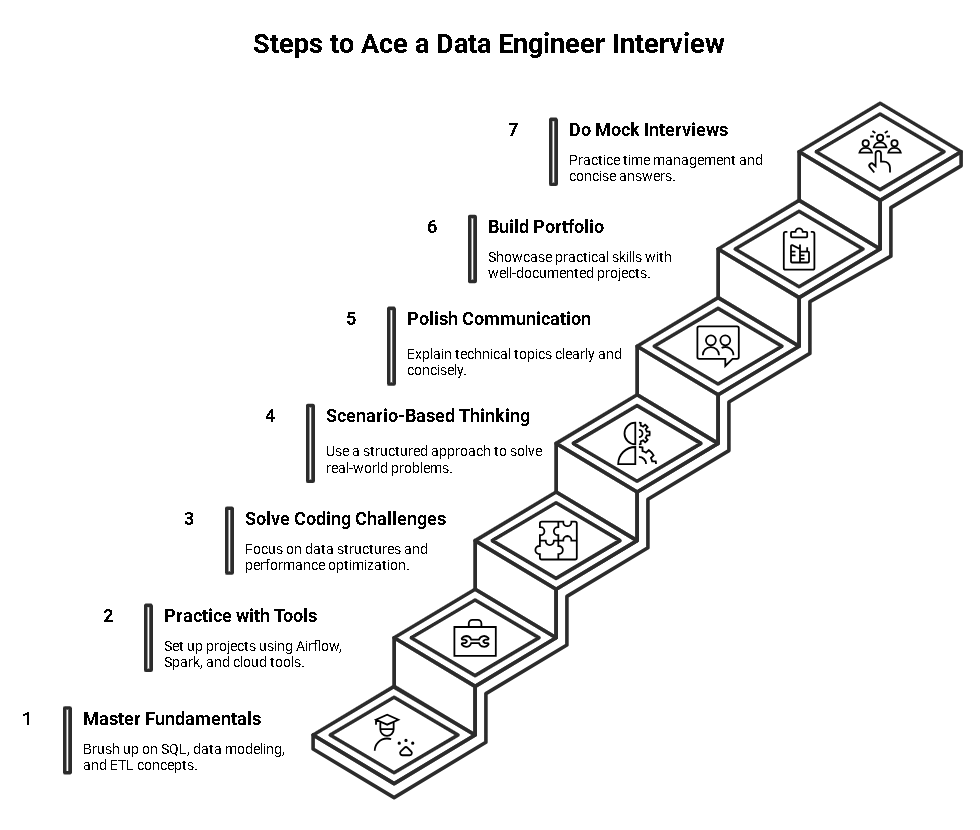
Landing a data engineer role takes both technical practice and smart preparation. Here’s how to get ready step by step:
1. Master the Fundamentals First
- Brush up on SQL because it shows up in almost every interview.
- Understand data modeling basics like star schema, normalization, and warehouse design.
- Review core ETL concepts and be able to design a simple pipeline from scratch.
2. Practice with Real Tools and Platforms
- Set up sample projects using Apache Airflow, Spark, or Kafka on free tiers or local environments.
- Use cloud tools like AWS Redshift or Google BigQuery with small datasets to learn the workflow.
- Build end-to-end mini-projects: data ingestion → cleaning → storage → reporting.
3. Prepare for Coding Challenges
- Solve SQL and Python challenges on platforms like LeetCode or HackerRank.
- Focus on data structures, error handling, and performance optimization rather than only syntax.
4. Practice Scenario-Based Thinking
- Take real-world problems—like pipeline failure or scaling for growth—and write down how you’d solve them.
- Use a structured approach: Identify → Analyze → Solve → Prevent.
5. Polish Communication Skills
- Practice explaining technical topics in simple terms to a friend or family member.
- Prepare short, clear answers for behavioral questions using the STAR method.
6. Build a Portfolio or GitHub Repo
- Upload sample pipelines, ETL scripts, or data models to show practical skills.
- A simple but well-documented project can make a big difference in interviews.
7. Do Mock Interviews
- Use platforms like Pramp or Interviewing.io for free practice sessions.
- Focus on time management while answering, so you stay concise.
Conclusion
Preparing for a data engineer interview isn’t just about memorizing questions—it’s about thinking like a problem-solver. Companies want engineers who can keep data moving reliably today and design systems that can handle tomorrow’s growth.
The best candidates combine technical depth with clear communication, quick decision-making under pressure, and the ability to explain the data’s business impact. If you focus on building real projects, practicing with real tools, and structuring your answers to show both skill and thought process, you’ll stand out in interviews.
Treat every interview as a conversation, not a test. Show curiosity, ask smart questions about the company’s data challenges, and position yourself as someone who doesn’t just write code—but builds solutions that last.


