

Data engineering used to be a single role. You’d move data from point A to point B, clean it up a little, and hand it off. But those days are long gone. Now, data teams are bigger, tech stacks are more layered, and the job has split into several specialized roles.
Some data engineers focus on building pipelines. Others manage cloud systems, help analysts, or prep data for machine learning. The title may be the same, but the work isn’t.
So read on. This guide breaks down the main types of data engineers you’ll find on modern teams, what they do, and how they fit into the bigger picture. Whether you’re hiring, job hunting, or just trying to understand who does what, this will clear things up.

Why Not All Data Engineers Are the Same
Data engineering has come a long way. What used to be one person’s job is now split across specialized roles. Why? Because data got bigger, tools got smarter, and businesses started asking for faster answers.
Let me explain. As companies shifted to cloud platforms and adopted tools like Snowflake, Databricks, and Airflow, the skill set required for “data engineering” exploded. One engineer might now spend all day building pipelines. Another might manage infrastructure. Someone else preps datasets for analysts or machine learning teams. Same title, very different jobs.
These roles didn’t appear by accident; they grew out of real needs. Big data created volume, cloud systems brought flexibility and scale, and modern data stacks demand specialization. So, instead of one generalist doing it all, companies now rely on focused engineers with deep expertise in specific areas. This shift has prompted organizations to rethink their strategies, fostering a collaborative environment where specialized teams work together to drive innovation. The evolving role of technology leaders has become crucial in navigating this landscape, as they must not only understand the technical nuances but also manage cross-functional partnerships effectively. By embracing these changes, companies position themselves to leverage data as a strategic asset, ultimately enhancing their competitive advantage.
Core Types of Data Engineers in Modern Workplaces
As data systems get more advanced, roles on data teams have become more specialized. Let’s break down the main types of data engineers today and what each one brings to the table. Among these specialized roles are data pipeline engineers, who focus on the architecture and optimization of data flows, and data modeling engineers, who design efficient data models to support complex queries and analysis. In order to build an effective infrastructure, an ideal data engineering team roles must also incorporate data quality engineers, who ensure the accuracy and reliability of data throughout its lifecycle. Together, these functions create a robust framework that empowers organizations to leverage their data effectively.
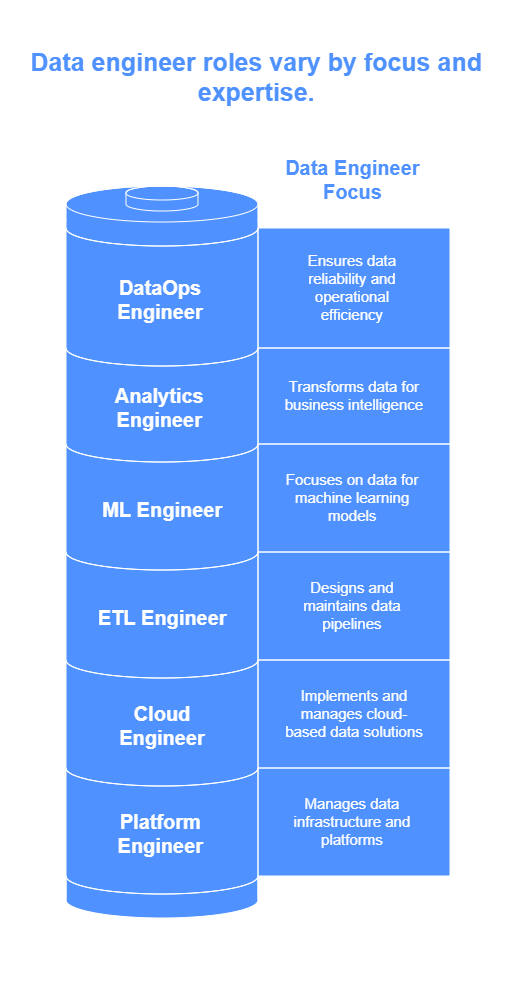
- Pipeline-Focused Data Engineer (ETL/ELT Engineer)
These engineers build the data highways. They create and manage pipelines that move data from different sources into storage systems where it can be used. Whether it’s real-time or batch processing, their job is to make sure data flows smoothly, accurately, and on schedule.
They work with tools like Apache Airflow, DBT, Apache NiFi, and Talend to automate and monitor these pipelines. Their focus is on reliability, transformation logic, and making sure the data gets where it needs to go in the right shape.
Common Use Cases: Financial systems syncing transactions, eCommerce platforms moving user activity logs, and SaaS companies connecting product usage data for internal dashboards.
- Platform/Data Infrastructure Engineer
This role is all about the plumbing behind the scenes. Platform engineers set up and maintain the cloud-based or on-prem systems that other engineers and data teams rely on. They build the foundation.
They’re focused on performance, scalability, and availability. Think Kubernetes for container orchestration, Terraform for infrastructure-as-code, Kafka for real-time data streaming, Spark clusters for distributed processing, and Snowflake for data warehousing.
Their job: They ensure that the system is always ready to handle more data, queries, and users without breaking.
- Analytics/BI Data Engineer
Analytics engineers make raw data useful. They work closely with business analysts and data consumers to clean, organize, and structure data into tables, models, and dashboards that make sense.
They use tools like SQL, Looker, Power BI, Tableau, and DBT to create business-friendly datasets and automated reporting pipelines. They understand both the technical side and the business questions behind the numbers.
Key strength: Translating messy, raw data into clean insights without asking the business to write code.
- Machine Learning (ML) Data Engineer
This engineer builds the data side of machine learning. They set up the pipelines that collect, transform, and serve features, so models can train and predict accurately.
They often work in Python and use tools like TFX, MLFlow, Kafka, TensorFlow, and Feature Stores. Unlike traditional data engineers, they work with both historical and real-time data, often experimenting with new workflows to improve model performance.
In short: They don’t build the models, but they make sure the data behind them is solid.
- DataOps / Data Reliability Engineer (DRE)
If the pipeline engineer builds the roads, the DataOps engineer checks for potholes. Their focus is on trust, making sure data is fresh, accurate, and reliable. They build systems for testing, alerting, and logging across the data stack.
They use tools like Great Expectations, Monte Carlo, Databand, and Soda to catch errors, track data health, and make sure nothing breaks silently.
Their mission: Prevent bad data from reaching dashboards, models, or stakeholders.
- Cloud Data Engineer
This role is built for the cloud. These engineers specialize in cloud-native data tools and manage everything from storage to compute to access control.
They often work inside platforms like AWS Glue, Google Cloud Dataflow, Azure Data Factory, BigQuery, and Redshift. They need a strong grip on cloud IAM, cost optimization, and performance tuning.
Their strength: Making cloud infrastructure scalable and secure while keeping costs under control.
Overlapping Skills and Differences
Not every data engineer does the same work, but many of them start with the same tools, skills, and mindset. There’s a common core that runs across all types, whether someone is building pipelines, prepping data for machine learning, or managing cloud infrastructure. Let me explain.
Shared Skills Across All Data Engineers
SQL as the Universal Language
SQL is non-negotiable. Whether you’re joining tables for reports, defining data models, or checking metrics for ML features, SQL is everywhere. It’s the one language every data engineer uses, no matter their specialty.
Python (or Scala) for Programming
Most data engineers use Python. It’s flexible, readable, and backed by powerful libraries. Scala is used in big data platforms like Spark, but Python leads the pack in scripting, automation, and even pipeline design.
Data Modeling and Warehousing
Understanding how data is structured- facts, dimensions, relationships is a must. Whether working with Redshift, BigQuery, or Snowflake, engineers need to think in terms of schemas and how data flows from raw to refined.
Version Control and Collaboration
Git isn’t just for software developers. Data engineers use it to track pipeline changes, review transformations, and sync across teams. CI/CD is growing too—especially when pushing tested code to production pipelines.
Awareness of Data Quality
Everyone is responsible for clean data. Whether through validation rules, automated tests, or alerts, engineers across the board watch for errors that can break dashboards or mislead models.
Key Differences Between Specialized Roles
Purpose and Focus
- Pipeline Engineers care about movement and transformation.
- Analytics Engineers shape data for reporting and business decisions.
- ML Data Engineers serve as features for models.
- Infrastructure Engineers build and manage the backbone systems.
Each role solves a different part of the puzzle.
Tooling and Tech Stack
Different jobs, different tools. One engineer might live in Airflow and DBT, another in Power BI and SQL, while someone else is deep in Kafka and Terraform. The toolset often defines the role.
Stakeholders and Team Integration
Analytics engineers talk to business teams, ML engineers work closely with data scientists, and platform engineers interact with DevOps. Who you talk to daily shapes how you think and what you build.
Responsibility for Production
Some roles push code to production often; others don’t. ML and pipeline engineers often monitor jobs, rerun tasks, or fix bugs in real time. BI-focused engineers may ship changes less frequently but must maintain accuracy.
Understanding both the shared foundation and where the paths split helps teams work smarter, not harder. And if you’re growing your data career or your data team, these insights can help you build with purpose.
How to Choose the Right Data Engineer for Your Team
Not every data engineer fits every need. Picking the right one depends on what your team is building, where your data is going, and who needs to use it. Let me explain.
Start with your goal. Are you trying to clean up messy data for dashboards? Build real-time pipelines? Serve features for machine learning? Each outcome points to a different type of engineer.
If your team needs:
- For data movement and transformation, hire a pipeline engineer. They’re best at building ETL/ELT workflows and making raw data usable.
- Clean datasets for reporting, hire an analytics engineer. They know how to structure data so business users can explore it without writing code.
- Scalable infrastructure, choose a platform engineer. They build the systems behind the scenes, think clusters, orchestration, and cloud optimization.
- Bring in an ML data engineer for feature pipelines and model-ready data. They understand how data feeds into training and prediction.
- Monitoring and quality checks are the look at a DataOps engineer. They keep data systems reliable and flag issues before they hit users.
Sometimes, you don’t need five different hires. For small teams or early-stage startups, one strong generalist who knows a bit of everything might be better than a narrow expert. But as your needs grow, specialization saves time and reduces risk.
Also, think about your tech stack. If you’re all-in on AWS, get someone who knows Glue or Redshift. If you’re using Snowflake and DBT, look for someone with those tools on their resume.
Hiring the right data engineer isn’t about checking boxes; it’s about matching skills to problems. Start with what you need solved, then work backwards to find the right fit.
Future Trends in Data Engineering Roles
Data engineering isn’t standing still. The tools are getting smarter, the roles are shifting, and the lines between jobs are starting to blur. Let me explain what’s coming and how it might affect your team or your career. As organizations increasingly rely on data-driven decision-making, the demand for versatile professionals is on the rise. This evolution means that many data scientists are now transitioning from data science to more integrated roles that encompass both engineering and analysis. Understanding these changes can empower you to adapt and thrive in this dynamic landscape.
1. Hybrid Roles Are Becoming the Norm
The days of clear-cut job titles are fading. Companies want engineers who can move across roles—someone who can write pipelines, shape analytics data, and work with cloud tools. That’s why titles like “full-stack data engineer” or “analytics+platform engineer” are showing up more often.
Teams are getting leaner, and people who can handle multiple tasks from ingestion to transformation to delivery are more valuable.
2. Data and DevOps Are Merging
Engineers are being asked to think more like software teams. CI/CD pipelines, containerization, and Git-based workflows are now part of many data projects. Data engineers are expected to build things that can scale, be tested, and deployed just like apps.
Knowing how to use tools like Docker, Kubernetes, or Terraform is no longer “nice to have.”
3. AI Is Automating the Boring Parts
AI is starting to automate data cleaning, schema detection, and even transformation logic. This doesn’t replace engineers—it just shifts their focus to higher-value work like architecture, design, and debugging edge cases.
If you’re still writing manual SQL for minor tasks, chances are that part of your job will be handled by a tool soon.
4. Real-Time Data is Now a Baseline
Batch processing won’t go away, but teams want faster insights. That’s why skills in streaming frameworks like Kafka, Flink, or Materialize are becoming more in demand. Even traditional dashboards are expected to update instantly.
Engineers who can think in real-time, not just in batches, are ahead of the curve.
5. Data Ownership Is Getting Decentralized
With concepts like Data Mesh and domain-owned pipelines, teams are moving away from centralized data departments. Now, the people closest to the data are expected to own it, including the pipelines and the quality checks.
More collaboration, more cross-functional ownership, and a bigger role for engineers embedded within product or business teams. This shift not only fosters innovation but also enhances the alignment between technical and business objectives. For teams to thrive in this environment, engineering manager essential skills become increasingly important, as they need to navigate complex communication between diverse stakeholders. Ultimately, empowering engineers within product teams can lead to more agile development processes and better overall outcomes for the organization. Additionally, fostering a culture of open communication and continuous learning is vital for teams aiming to maximize their potential. As engineers take on greater responsibilities, they also require support in navigating engineering career growth, ensuring they are equipped with the necessary skills and opportunities to advance. This holistic approach not only benefits individual team members but also contributes to the long-term success of the organization as a whole.
If you’re building a team or a career, these trends can be your edge. Focus on versatility, automation, and system thinking. The more you adapt now, the more in-demand you’ll be later.
Conclusion
Data engineering today is about more than pipelines; it’s about building the right systems, serving the right teams, and solving the right problems. As roles become more focused, the real edge lies in clarity: who’s responsible, how pieces fit together, and what drives impact.
If you’re hiring, define the outcome first, then find the skills that support it.
If you’re growing your career, master the fundamentals and stay close to real-world problems. Tools will change, but the value of clean, reliable data won’t.
And here comes the good part: The best data engineers don’t just build—they bring clarity to complexity. That’s what makes them impossible to ignore.


